05. Counter
function counter(f) {
var a = f(), b = f();
return a() == 1 && a() == 2 && a() == 3
&& b() == 1 && b() == 2;
}В этой задаче нужно написать функцию, которая бы возвращала функцию-счётчик, при вызове которой, в свою очередь, возвращалась сначала единица, затем двойка, тройка и так далее.
Довольно простая задача. Например, ответ мог бы быть таким:
function() {
let x = 1;
return function() {
return x++;
}
}И это вполне себе решение. Если убрать все пробельные символы и вытянуть код в строчку, получим 50 символов:
counter(function(){let x=1;return function(){return x++;}})Ясное дело, что в первую очередь нам тут нужно заменить всё на анонимные функции:
counter(()=>{let x=1;return ()=>x++})28! Неплохо. Но, судя по таблице результатов, можно упростить аж до 11 символов:
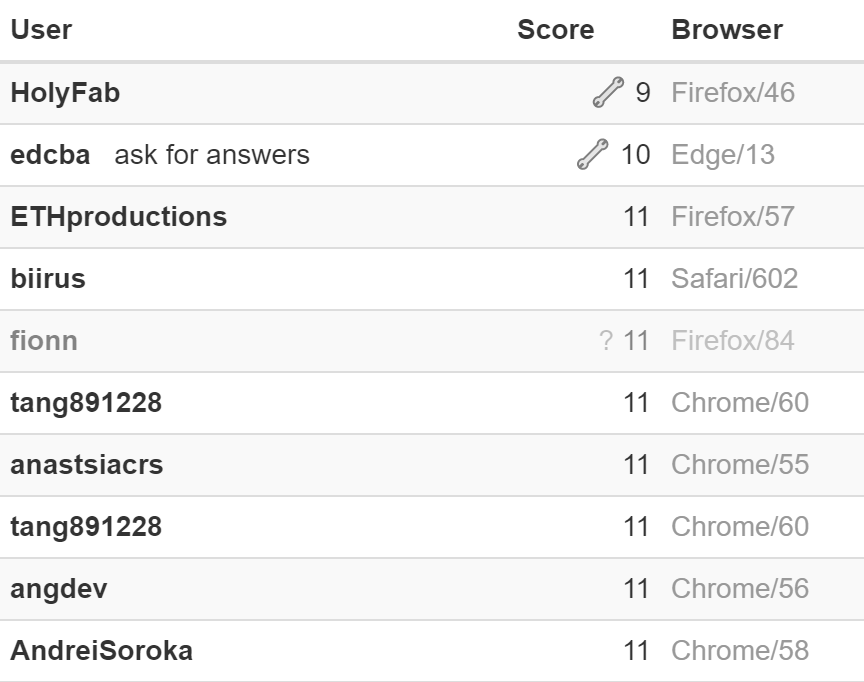
Больше всего в текущем решении смущают let и return. Явно надо избавляться как-то от них. Если мы просто удалим let, оставив x без него, то код не заработает:
> counter(()=>{x=1;return ()=>x++})
falsex в таком случае объявляется не как локальная переменная функции, а как свойство глобального объекта (window, ибо мы в браузере). И каждый вызов внутренней функции переиспользует имеющийся счётчик, а каждый вызов внешней функции — сбрасывает его. Интересная фича, но не то, что нам нужно.
Однако, если нам нужно, чтобы x стал локальной переменной, достаточно просто передать его в качестве параметра:
counter(x=>{x=1;return ()=>x++})Теперь присваивание работает только в рамках функции, а потому переменная не переиспользуется между всеми вызовами. Ну и, да, 23 символа.
С let разобрались, а значит нужно как-то избавляться от return.
В анонимной функции можно не использовать фигурные скобки и return, если вместо тела написать выражение, результат которого она должна вернуть. Но у нас ведь два выражения в функции, потому просто удалить return мы не можем.
Но можем использовать запятую. Оператор , вычисляет и левую, и правую часть, но возвращает только результат вычисления правой. А это как раз то, что нам нужно: объявить переменную и вернуть функцию.
Взять и убрать фигурные скобки, да заменить return на запятую мы не можем:
> counter(x=>x=1,()=>x++)
falseТогда это просто будут две функции, записанные через запятую. Скобки всё же придётся добавить. Но круглые:
counter(x=>(x=1,()=>x++))16 символов! Мы всё ближе.
С лёгкостью можем выиграть ещё один символ, заменив скобки вокруг параметров внутренней функции на какой-то параметр. На нижнее подчёркивание, например:
counter(x=>(x=1,_=>x++))Правда, это всё ещё не 11.
Мы не можем никак избавиться от того факта, что у нас есть внешняя и внутренняя функция. И вроде никак не можем избавиться от инкремента. Но можем вместо определения x внутри функции, указывать для него значение по умолчанию:
counter((x=1)=>(_=>x++))Правда, это заставляет нас добавлять скобки вокруг параметров внешней функции. Но зато можно убрать их вокруг внутренней, т. к. тело внешней у нас теперь состоит только из определения внутренней:
counter((x=1)=>_=>x++)Скобки туда, скобки сюда, и получили мы 13 символов. Совсем близко.
Точно можно сократить ещё два символа, и это явно должны быть =1. Но если мы их просто уберём, то работать ничего не будет:
> counter(x=>_=>x++)
falseУ нас ведь теперь x по умолчанию равен undefined, а при увеличении его на единицу мы получаем NaN. Дальше, увеличивая NaN, получаем снова его, и так далее. Значит, нужно как-то обработать первое присваивание, чтобы не падать в этот NaN-цикл. Можем сделать так:
counter(x=>_=>x=++x||1)Теперь, даже если мы получаем NaN при приведении undefined к числу, мы всё равно присваиваем единицу.
Однако, это 14 символов. Нужен какой-то способ, который позволит превратить undefined в ноль, а затем увеличить его на единицу. Кажется, тут снова может помочь приведение типов.
Как мы уже уяснили, приведение undefined к числу нам не поможет, ибо получим NaN. Значит унарный плюс бесполезен:
> +undefined
NaNВозможно нам помогло бы каким-то образом отрицание, ибо:
> !undefined
trueИ если сделать двойное отрицание, то мы бы получили ноль. Но проблема в том, что вот в такой записи:
x=>_=>x=!!x+1Мы получим единицу при первом вызове внутренней функции, а затем всегда будем получать только двойку, ибо x в первой части выражения во всех вызовах кроме первого будет приводиться к единице.
У нас остался ещё один оператор, который часто используется в разных хаках — битовое «не»:
> ~undefined
-1И вот он даёт что-то интересное. Если мы применим его дважды, то получим:
> ~~undefined
0Как раз то, что нам нужно. А поскольку двойное отрицание для числа возвращает само число, то подобная конструкция работает не только для первого вызова внутренней функции, но и для всех последующих.
Получается, что решение в 13 символов выглядит следующим образом:
counter(x=>_=>x=~~x+1)В примерах про использование undefined с разными унарными операторами можно заметить полезное для нас свойство побитового отрицания:
> ~0
-1
> ~1
-2
> ~2
-3
> ~undefined
-1Получается, что после использования побитового отрицания мы получаем необходимое для функции-счётчика число, просто с противоположным знаком. А раз так, то почему бы не сократить решение ещё немного:
counter(x=>_=>x=-~x)Вжух! 11 символов.
Если посмотрим на таблицу результатов, то увидим там даже ребят с 9-символьными решениями:
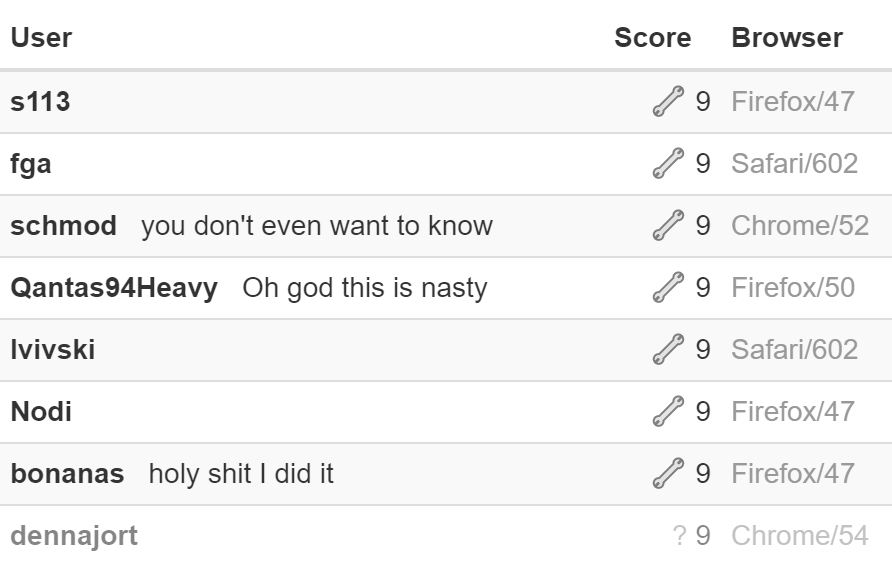
Но все они схитрили, подставив в качестве выражения, возвращаемого из внешней функции, prompt. Так, каждый вызов внутренней функции становился вызовом prompt и позволял ввести нужное значение, которое затем и использовалось в сравнении.
Хитро! Но автор игры это уже пофиксил, потому мы не сможем использовать такую лазейку. А раз так, то можно остановиться на решении в 11 символов.
Можно остановиться и обсудить вот что. Как так вышло, что undefined после побитового отрицания превратился в 0, а не в NaN, как в случае использования унарного плюса? И как вообще происходит побитовое отрицание, если мы обсуждали ранее, что числа в Джаваскрипте хранятся в виде знака, мантиссы и периода, как это завещал IEEE 754. Какие же биты в таком случае инвертируются?
Дело в том, что побитовые операции в Джаваскрипте работают не совсем так, как арифметические. Чтобы в этом разобраться, сперва обсудим, как работает побитовое отрицание, не глядя на его реализацию в Джаваскрипте.
Когда мы разбирали четвёртую задачу, то моделировали разные способы хранения чисел в памяти. Там мы пришли к тому, что чтобы хранить целые знаковые числа в 16-битном формате, нужно старший бит выделить под знак:
{|0|000 0000 0111 1011}
↑
signИ в таком формате 123 и −123 отличаются друг от друга только первым битом:
123 = {0 000 0000 0111 1011}
-123 = {1 000 0000 0111 1011}А теперь предположим, что мы хотим сложить эти два числа, имея только их битовое представление. Если мы просто будем складывать каждый бит друг с другом справа налево (в столбик), то получится какая-то шляпа:
{0 000 0000 0111 1011}
+ {1 000 0000 0111 1011}
= {1 000 0000 1111 0110} = -246Сложение как операция происходит внутри компьютера сложнее, чем кажется на первый взгляд. Посмотрите «Как компьютеры складывают числа», чтобы понять, что к чему. (Ссылка может не работать без VPN.)
Мы сложили 123 и −123, а получили −246. Да, наверное мы зря складывали старшие биты, они ведь знаковые. Но если бы не складывали, результат не стал бы лучше. Почему так происходит?
Как минимум потому, что мы неправильно реализовываем сложение. Если бы у нас были два положительных числа, всё сработало бы нормально:
{0 000 0000 0111 1011}
+ {0 000 0000 0111 1011}
= {0 000 0000 1111 0110} = 246Как и с двумя отрицательными (хотя тут как-то и не понятно, как вычислять знаковый бит):
{1 000 0000 0111 1011}
+ {1 000 0000 0111 1011}
= {1 000 0000 1111 0110} = -246Но имея положительное и отрицательное число, как и в школьной математике, при их сложении мы должны вычесть из положительного отрицательное:
{0 000 0000 0111 1011}
- {1 000 0000 0111 1011}
= {0 000 0000 0000 0000} = 0Однако, реализовывать вычитание как отдельную операцию на машинном уровне — дорого. И лучше пойти другим путём.
Если вы посмотрели видео «Как компьютеры складывают числа», то скорее всего понимаете, что для вычитания потребовались бы отдельные части АЛУ, отличные от сумматоров.
Вычитание — это сложение уменьшаемого с вычитаемым, где у вычитаемого инвертирован знак. Примерно так это работает и внутри компьютера, только вместо отрицания вычитаемого, числа переводятся в обратный код. В отличие от прямого кода, который мы использовали ранее, в нём незнаковые биты отрицательных чисел инвертируются.
Вот как выглядел бы обратный код для числа −123:
-123 = [1 111 1111 1000 0100]Чтобы не путаться, будем биты в обратном коде заключать в квадратные скобки.
Теперь, если мы захотим сложить 123 и −123, то выглядеть это будет так:
[0 000 0000 0111 1011]
+ [1 111 1111 1000 0100]
= [1 111 1111 1111 1111]Инвертировать биты 123 не нужно. Обратный код положительного числа совпадает с его прямым кодом.
Ответ при сложении получается тоже в обратном коде. Поскольку он получился отрицательным, то чтобы перевести его в прямой, нужно снова инвертировать все биты, кроме знакового:
[1 111 1111 1111 1111] = {1 000 0000 0000 0000}
= -0Обратный код прост для понимания, но с ним есть проблема. Если вдруг вычитаемое меньше по модулю, чем уменьшаемое, то приходится переносить единицу.
Допустим, нам нужно вычесть из 123 число 120. Значит, надо сложить 123 и −120:
123 = {0 000 0000 0111 1011}
-120 = {1 000 0000 0111 1000}Так как −120 — отрицательное, то сперва инвертируем все его биты, кроме старшего:
-120 = {1 000 0000 0111 1000}
= [1 111 1111 1000 0111]Теперь выполняем сложение:
[ 0 000 0000 0111 1011]
+ [ 1 111 1111 1000 0111]
= [1 0 000 0000 0000 0010]Самая левая единица не влезла в отведённое для неё место. В случае возникновения такой ситуации, компьютеру нужно взять эту единицу и добавить к получившемуся результату:
[0 000 0000 0000 0010]
+ [0 000 0000 0000 0001]
= [0 000 0000 0000 0011]
= 3И только после этого получается правильный ответ — 3. Результат получился в обратном коде, но поскольку число положительное, то ничего инвертировать не нужно.
Вот эта дополнительная обработка переноса единицы добавляет головной боли. Потому, вместо обратного кода, стали использовать дополнительный.
Для перевода отрицательного числа из прямого кода в дополнительный, переводят его сперва в обратный, а затем к модулю числа добавляют единицу.
Рассмотрим тот же пример: 123 − 120.
123 = {0 000 0000 0111 1011}
-120 = {1 000 0000 0111 1000}Сперва переведём −120 в дополнительный код. Для этого инвертируем все биты кроме знакового, получая обратный код, а затем добавим единицу к модулю получившегося значения:
-120 = {1 000 0000 0111 1000}
= [1 111 1111 1000 0111]
= (1 111 1111 1000 1000)Как и в случае с обратным кодом, введём для дополнительного свои скобки — круглые.
Теперь прибавим это к 123:
( 0 000 0000 0111 1011)
+ ( 1 111 1111 1000 1000)
= (1 0 000 0000 0000 0011)
= (0 000 0000 0000 0011)
= 3У нас снова «вылез бит». Но теперь мы ничего с ним не делаем, и просто отбрасываем. Тем самым мы получаем в ответе 3.
В случае, если уменьшаемое меньше, чем вычитаемое, дополнительный код тоже работает:
100 - 120 = 100 + (-120) (0 000 0000 0110 0100)
+ (1 111 1111 1000 1000)
= (1 111 1111 1110 1100)
= [1 111 1111 1110 1011]
= {1 000 0000 0001 0100}
= -20Тут мы получили отрицательное число в дополнительном коде. Сперва отнимаем от него единицу, получая обратный код. А затем инвертируем биты и получаем прямой код, или −20.
К слову, чтобы не запоминать, когда единицу нужно добавлять, а когда отнимать, можно при переводе из прямого в дополнительный и из дополнительного в прямой всегда сперва инвертировать биты, а затем добавлять единицу к модулю числа.
Да, на преобразование отрицательного числа в обратный код уходит меньше времени, чем на преобразование его в дополнительный. Но сложение дополнительных кодов быстрее, чем обратных, ибо не нужно обрабатывать перенос. А потому компьютеры в большинстве своём хранят целые числа сразу в дополнительном коде. Это позволяет упростить операции сложения и вычитания (поскольку нужна только операция сложения), и тем самым упростить архитектуру вычислителя.
Обратный и дополнительный коды — это сущности из мира целых чисел. Как мы помним, Джаваскрипт оперирует числами с плавающей запятой, а потому ничего не хранит в дополнительных кодах. Однако, когда речь заходит о побитовых операциях, Джаваскрипт приводит имеющиеся операнды к 32-битным целым (со знаком или без), проводит над ними необходимую операцию, а затем переводит результат в 64-битное число с плавающей запятой.
Тут сразу может возникнуть вопрос, почему операции происходят над 32-битными целыми, а не над 64-битными? Но ответ на него очевиден. 64-битные целые не всегда можно перевести в формат с плавающей запятой без потерь:
> 2 ** 64 - 1
18446744073709552000
> 2 ** 64 - 2
18446744073709552000А все 32-битные целые вполне влезают в имеющиеся ограничения.
Теперь мы знаем, как работает сложение чисел в дополнительном коде, и понимаем, что при работе с побитовыми операциями Джаваскрипт сперва переводит числа в 32-битные целые, а затем обратно в число двойной точности. А раз так, то посмотрим, как работает оператор побитового отрицания.
Согласно спецификации, если имеем ~x, то:
Если
xтипа BigInt, то возвращаем-x - 1.Если не BigInt, то приводим значение к типу, обозначенному в спецификации как Int32.
Для получившегося числа вычисляем
-x - 1.
-x - 1 — это арифметическое представление инвертирования битов и перевода дополнительного кода в прямой.
Предположим, что у нас есть всё то же число 123, и мы решили вычислить ~123. Согласно этому алгоритму, мы должны получить −124. Джаваскрипт подтверждает:
> ~123
-124Дополнительный код 123 — (0 000 0000 0111 1011), и если в нём инвертировать биты, как это должен делать оператор ~, то получим (1 111 1111 1000 0100). Какое-то число в дополнительном коде. Переведём его в прямой:
(1 111 1111 1000 0100)
= [1 111 1111 1000 0011]
= {1 000 0000 0111 1100}
= -124Получили −124, как и ожидалось.
Если попробовать инвертировать какое-нибудь большое число, то результат может получиться странным:
> ~-5_000_000_000.1
705032703Не совсем -x - 1, да?
А всё потому, что это не BigInt, а потому значение сперва приводится к Int32. А ToInt32(x) выглядит так:
Приводим
xк типу Number по обычным правилам.Если после приведения значение
xравно NaN, ±0 или ±∞, то возвращаем 0.Отбрасываем дробную часть
x.Находим остаток от деления на 2^32 (знак остатка — положительный).
Если полученный остаток больше 2^31, то отнимаем от него 2^32.
Возвращаем то, что получилось.
Вот тут мы видим, кстати, почему при применении побитового отрицания к undefined мы не получаем NaN. Потому что он на втором шаге превращается в 0.
В нашем примере первым делом отбросится дробная часть числа:
-5_000_000_000.1 → -5_000_000_000Затем вычислится положительный остаток от деления числа на 2^32:
-5_000_000_000 mod 2^32 = -5_000_000_000 mod 4_294_967_296
= 3_589_934_592Получив остаток от деления (3_589_934_592), проверяем, больше ли он чем 2^31 (2_147_483_648). Больше. Потому мы вычитаем из него 2^32:
3_589_934_592 - 2^32 = 3_589_934_592 - 4_294_967_296
= -705_032_704Наконец, инвертируем знак этого получившегося числа и вычитаем из него единицу. Получаем ответ: 705_032_703.
О чём ещё тут можно было бы упомянуть, это о том, что такое положительный остаток, который мы выше высчитывали. Несмотря на то, что «остаток от деления» — это что-то из курса математики за четвёртый класс, всё не так просто, как кажется на первый взгляд.
Нет никаких проблем найти остаток от деления, когда работаем с двумя положительными числами. При делении 52 на 6 получаем в неполном частном 8 и 4 в остатке:
52 = 8 * 6 + 4Однако, что, если мы будем делить −52 на 6?
-52 = -8 * 6 + (-4)
-52 = -9 * 6 + 2Внезапно появляются два возможных результата. Смотря какой будет остаток от деления — положительный или отрицательный. Потому, когда мы обсуждаем алгоритмы, зачастую нужно уточнять, о каком именно остатке идёт речь.
Некоторые языки программирования поддерживают несколько операций для поиска остатка от деления. Так, в Хаскеле есть как mod так и rem:
> mod (-52) 6
2
> rem (-52) 6
-4При делении с остатком в этих операциях используется разное «усечение»: к нулю или к −∞. Так, rem делает целую часть ближе к нулю, а mod — к −∞. Иными словами, при rem знак остатка совпадает со знаком делимого, а при mod — со знаком делителя.
Если же говорить про Джаваскрипт, то в нём только одна операция для поиска остатка от деления — %. И в ней знак остатка совпадает со знаком делимого (аналогично rem):
> -52 % 6
-4
> 52 % -6
4Напоследок можно сказать ещё вот о чём.
Иногда в целях дебага нужно найти битовое представление числа. Если нужно 32-битное представление переданного числа как целого, то подойдёт вот такая функция:
function getInt32Binary(n) {
return (n >>> 0).toString(2).padStart(32, '0');
}Здесь n >>> 0 означает, что мы сдвигаем ноль битов вправо. То есть, никакого сдвига по факту и не происходит. Однако, из-за этой операции число неявно приводится к беззнаковому 32-битному целому.
А если мы хотим посмотреть на то, как выглядит число в Джаваскрипте по стандарту IEEE 754, то можем использовать вот такую запись:
function getFloat64Binary(n) {
const uint32 = new Uint32Array(new Float64Array([n]).buffer);
return getInt32Binary(uint32[1]) + getInt32Binary(uint32[0]);
}